
Table of Contents
As a field and consulting engineer, I have witnessed the evolution of data center technologies firsthand, from traditional bare-metal server deployments and virtualized cluster environments to the growing demands on storage and the convergence of compute and storage. My experience with hyperconverged environments using Cisco and Nutanix HCI solutions has led me to realize that we need a new definition.
HCI usually stands for “hyper-converged infrastructure.” But do we really understand the true essence and impact of the technology? HCI radically changes data center architecture by eliminating centralized network storage and consolidating storage and compute resources into a single standard server node. The nodes are clustered, virtualized, and overlaid with distributed HCI software that abstracts and aggregates the capacity of all nodes into a shared resource pool.
Of course, all resources are software-defined and managed via a simple Web UI. The result is a drastic simplification of the data center architecture, increased utilization and efficiency through higher consolidation, the ability to define storage properties per VM disk, lower total cost of ownership, etc.
But there’s much more to HCI than resource consolidation and management simplification provided by Cisco UCS-X modular systems, Intersight cloud-management, and future-proof Nutanix HCI architecture. We argue that HCI should stand for “hybrid cloud infrastructure!” Let’s explore the five underlying, less obvious, but future-impacting HCI design cues.
1. Incremental storage capacity expansion
Imagine not having 70 percent of storage go unused (wasted) for the first three years.
HCI fundamentally changes the way you manage your data center growth. We traditionally purchase storage systems that last more than five years. Plus, we always add buffer capacity margins, just in case. As a result, the storage system is extremely underutilized initially.
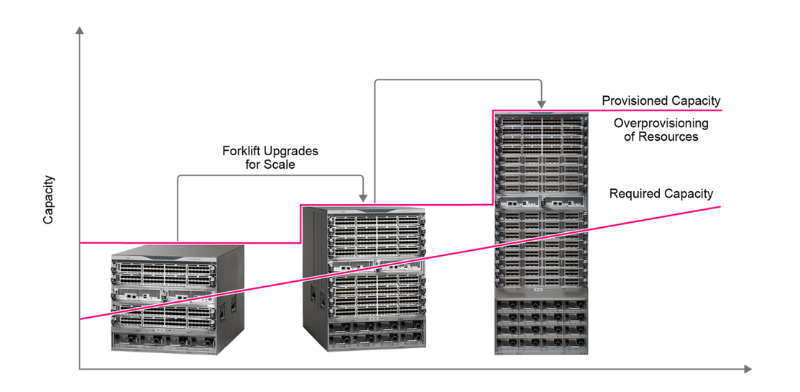
So, instead of buying in advance many resources that slowly (if ever) get fully utilized, you can optimally expand your infrastructure footprint by buying what you really need (a capacity node or a performance storage node) when you actually need it. This way you avoid relying on your magic ball and eliminate forklift upgrades. Essentially, you’re wasting fewer resources by avoiding overprovisioning of idle capacity on Day 1.
Fun fact: Nutanix (as of recently) also supports adding external third-party storage systems, such as those from Everpure.
2. Software-defined infrastructure always evolves
Do you know about the data center Fountain of Youth? Your existing infrastructure cluster can get better over time!
Moving advanced features processing (data efficiency and tiering, network functions, security mechanisms, etc.) to software enables your HCI stack to stay in shape by relying on over-the-air upgrades for new features, hardware compatibility, and security posture.
It’s not just about features. With this approach, you can also boost your data center performance by receiving HCI software stack optimization patches*. This process is similar to how you can unlock extra engine power with a simple over-the-air software update in modern cars.
3. Heterogeneous (disaggregated) hardware systems
We all know that a motherboard or power failure will take down all servers’ resources (CPU, RAM, storage) with it. But did you know it doesn’t have to be this way?
While everything is getting software-defined, at the same time we are witnessing the rise of domain-specific hardware accelerators such as the data processing unit (DPU) and even application-specific processors (thanks to the RISC-V open architecture) to speed up specific workload processing and jump over the Moore’s Law speed bump that’s ahead of us.
Aside from accelerators, we have a trend toward fully decoupled hardware systems, with dedicated resource-specific hardware nodes: compute, memory, and storage nodes. Resource-specific nodes are aggregated into resource pools. Heterogeneous hardware systems are enabled with mechanisms such as Compute Express Link (CXL) with which CPUs and accelerators share memory and cache coherently. Memory can be attached as a shared, fabric-accessible resource rather than being stranded on individual servers.
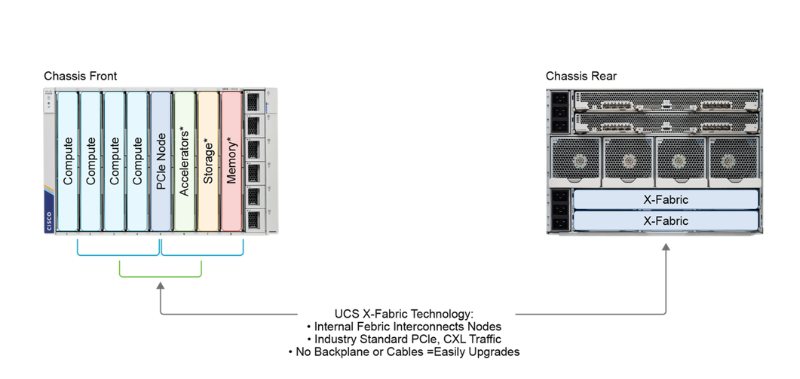
The reasoning here is that when upgrading, we might not need additional CPU—just more RAM capacity or more storage. So, you can upgrade your infrastructure more optimally without purchasing resources you don’t need.
This disaggregated hardware approach also fundamentally changes your data center operations and reliability. B separating specific resources into dedicated nodes, we create smaller failure domains. For instance, CPU failure will not take storage and RAM resources down with it.
We already have elements of this disaggregated hardware with UCS-X architecture, which (besides regular compute nodes) provides storage nodes and decoupled scalable networking with UCS-X Fabric. You can find your optimal X-Series node here. And who knows what the future holds? Think of advanced networking with optical switching, future dedicated nodes with domain-specific accelerators, and more!
Note: For more details, visit Cisco Compute Hyperconverged X-Series System with Nutanix.
4. Evolvable infrastructure
Gmail has been working steadily for over 20 years. Can you imagine how many times Google has completely replaced the underlying infrastructure without ever causing application service downtime?
Hyperscalers have been using HCI-like infrastructure for decades (including compute/storage/network resource pooling and horizontal scaling) with their own internal stacks and tooling. Additionally, to turbo-charge their HCI solution, they rely heavily on custom hardware/software co-design (custom offloads for networking and storage processing). And of course, in terms of configuration and management, everything is software-defined.
If we think of hyperscalers as F1 cars (serving as R&D platforms) and our enterprise data centers as regular, everyday cars, we can surmise that this innovative architecture is bound to trickle down to our enterprise data centers.

HCI enables an evolvable infrastructure that prevents you from having to throw anything away. Rather, it gradually upgrades your cluster with newer nodes. It’s fine to mix nodes with varying performance and capacity levels, like grooming a plant ecosystem by gradually replenishing your garden. Eventually, you will remove some nodes from the cluster (when a node dies due to age or you decide to repurpose it after about 10 years to a testing cluster), but this will typically happen much later than with our current (~5-year) upgrade cycle. So essentially, you’ll get more time and resources from your valuable investment while being more eco-friendly!
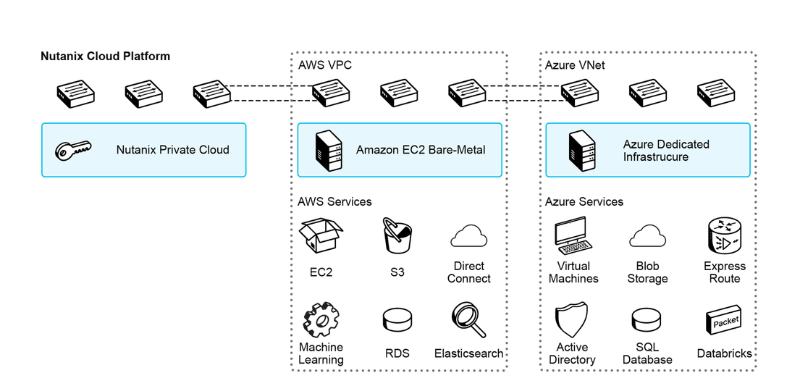
5. Plug your HCI cluster into public clouds
One more thing: once you have your cloud on the ground, powered by Hyperscalers’ DNA, you can more easily plug it into a hyperscale cloud. It’s not marketing fluff; it’s a real product. For example, Nutanix Clusters allows you to run 100% native Nutanix HCI on rented bare-metal servers of AWS, Azure, and GCP.
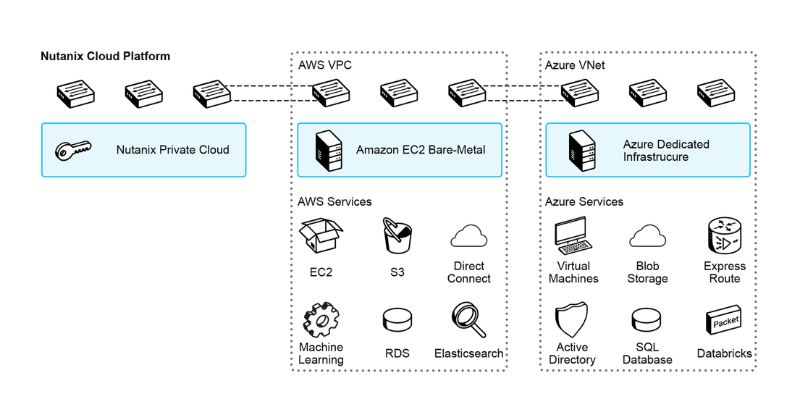
This way, you’re switching to an OPEX model by renting both the hardware and the software license. Additionally, Nutanix Clusters unlock the following features:
- A single pane of glass to manage both on-prem and cloud-based infrastructure footprints
- Ability to migrate your applications between on-prem and cloud environments without worrying about silly details such as disk formats
- Even your networking constructs (Virtual Network in Nutanix, VPC/VNET in Hyperscalers) are normalized, i.e., translated automatically
Test Nutanix now
So, do you want a test drive? There’s no need to schedule (and no driving license needed). Just your email address: Take a quick Nutanix Test Drive.
To stay tuned, follow our NIL Learning Knowledge Library or watch the Cisco Live session about this topic:
For more general details about Cisco & Nutanix Solutions, visit this page. To find out more about Cisco and Nutanix collaboration, read: The next chapter of Cisco and Nutanix: Building flexible infrastructure for the modern era.
And lastly, if you are still evaluating or already implementing HCI and need expert training, you can check out our existing training offering or reach out to us if you would like something different (LS_Sales_Support@nil.com). Our team has 33 years of experience creating and delivering IT training and vast experience in deploying data center and HCI systems.
*For example, Nutanix AOS 5.20 offered significant performance boosts, primarily through smarter Oplog handling for better sequential writes (doubling performance in some cases) and vDisk sharding, which dramatically improved random read performance (up to 172% gain) and database transaction rates (up to 78% gain) by optimizing CPU usage for small I/O. And this was provided free of charge to all existing users via a simple over-the-air update!
Read next:
The next chapter of Cisco and Nutanix: Building flexible infrastructure for the modern era