
Table of Contents
[ad_1]
By teaching large language models to reason through pharmacological pathways, PromptSE could help improve the accuracy, interpretability, and biological plausibility of drug-safety screening.

PromptSE: drug side effect prediction with LLM-derived pharmacological representations. Image Credit: MeshCube / Shutterstock
In a recent paper published in the journal Scientific Reports, researchers present PromptSE as a potential solution to current limitations in anticipating adverse drug side effects. PromptSE is a novel hybrid computational framework that was designed to combine the semantic reasoning capabilities of LLMs with the predictive precision of deep learning algorithms.
Study findings revealed that by guiding the AI to evaluate the biological mechanisms that may underlie symptoms, this novel approach improved performance over several traditional side-effect-predictive models. These findings suggest that PromptSE and similar AI frameworks could pave the way for safer drug development and potentially enable more reliable computational tools for pharmacological screening.
Background
Despite decades of research in the field, anticipating adverse drug reactions remains a significant challenge in modern healthcare. Unintended reactions to therapeutic drugs are currently ranked fourth amongst the leading causes of mortality, trailing only behind cardiovascular disease (CVD), cancer, and infectious illnesses.
While identifying risks in laboratory settings is technically possible, it is known to be prohibitively expensive and time-consuming. Consequently, researchers predominantly rely on computational models to predict whether a specific drug might trigger a specific adverse reaction.
Unfortunately, reviews on the topic suggest that these models are significantly limited by current data quality. While well-structured data on chemical compounds is readily available, information on side effects is often buried in unstructured clinical narratives and spontaneous symptom reports, severely hampering the accuracy of traditional computational models.
Furthermore, while artificial intelligence has been proposed as a potential solution to this problem, research has shown that older machine learning algorithms tend to focus on the most frequently mentioned symptoms and often overlook the underlying biological mechanisms that may contribute to the adverse reaction.
About the research
The research aimed to overcome the limitations of LLMs as basic text encoders by developing PromptSE, a dynamic reasoning artificial intelligence framework built using a multi-stage prompting technique.
The prompt was designed to guide the model to evaluate side effects across their: 1. Administration route, 2. Metabolism pathways, 3. Structural properties, and 4. Target selectivity, thereby leveraging PromptSE to infer mechanism-relevant explanations for an adverse event rather than relying only on superficial symptom descriptions or frequent patterns from the training dataset.
PromptSE was trained using a combined “labeled drug side effect dataset” derived from the DrugBank and SIDER databases and comprised a total of 1,020 drugs and 5,599 side effects.
Once the LLM generated mechanistic profiles based on this data, Biomedical Bidirectional Encoder Representations from Transformers (BioBERT), a separate AI model specialized in processing medical, clinical, and biological texts, was used to convert the generated profiles (text) into mathematical vectors, which were subsequently fed into a deep learning module to predict drug-side effect associations.
For rare drugs and side effects with limited data, the Hierarchical Graph Convolutional Network (HiGCN) was used to enable low-frequency entities to borrow contextual clues from more common, well-documented medications or side effects, thereby augmenting model accuracy while reducing the risk of degrading better-supported representations.
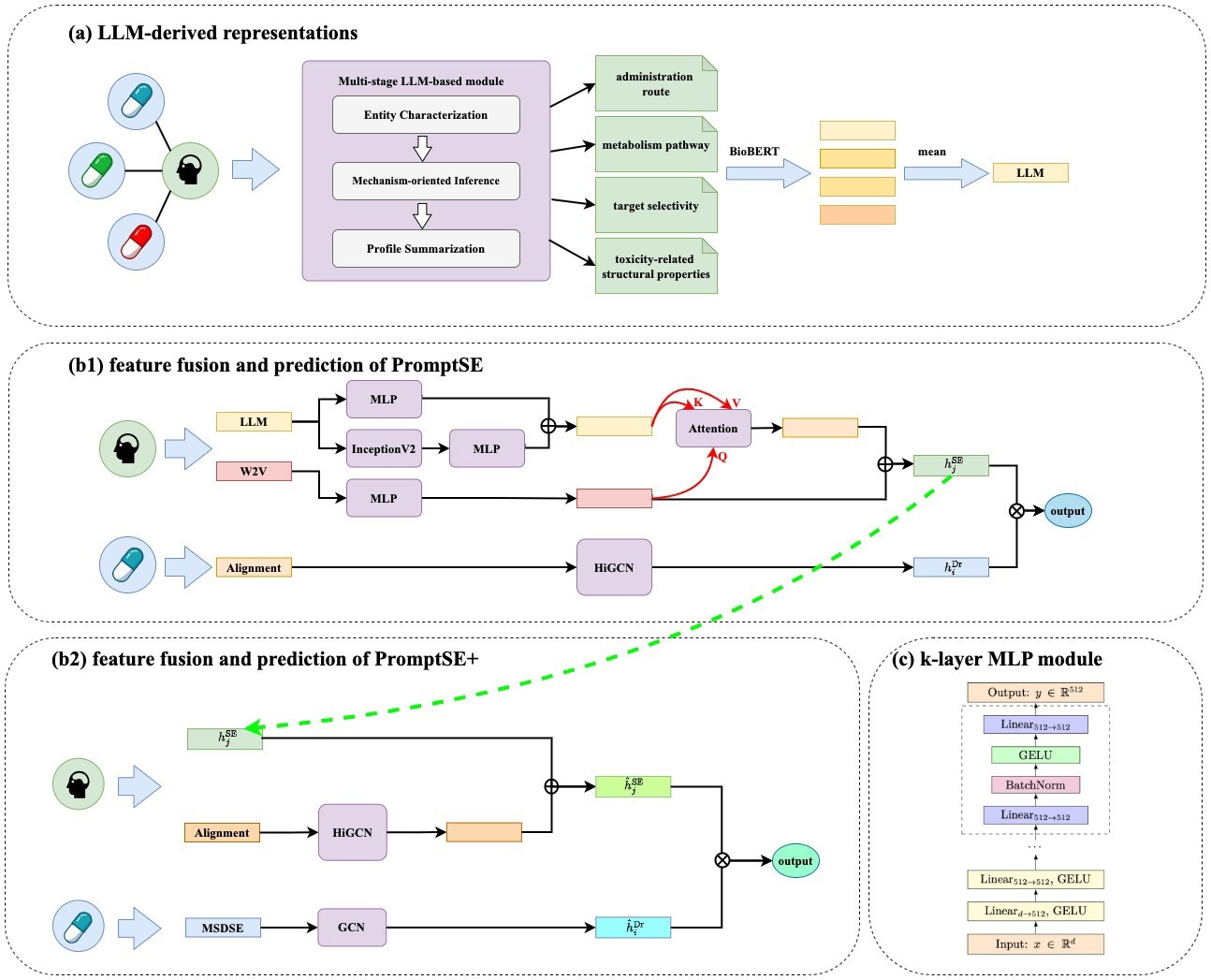
Overview of PromptSE and PromptSE+Framework.(a) LLM-derived representations, where side-effect profiles are generated using stepwise LLM reasoning and embedded with BioBERT. (b1) PromptSE’s feature fusion and prediction stage, combining LLM-derived and Word2Vec side-effect features with alignment drug vectors refined by HiGCN.(b2) PromptSE+’s feature fusion and prediction stage, replacing alignment drug vectors with advanced drug features from MSDSE for enhanced performance. (c) The general k-layer MLP architecture used in (b1) and (b2)
Findings
The research findings revealed that the dataset was highly skewed towards unknown adverse associations, with only 2.34% of the possible drug-side effect pairs labeled as known positive associations. Consequently, the Area Under the Precision-Recall Curve (AUPR) was used to measure PromptSE’s accuracy alongside AUC, Macro-F1, and Matthews Correlation Coefficient.
AUPR analyses revealed that PromptSE achieved an AUPR of 0.6551 and outperformed the strongest non-drug-informed baseline by 9.26%, despite being provided only with side-effect data and association-derived drug alignment features rather than direct drug properties. Furthermore, when the model was augmented with multi-modal drug information, performance was observed to improve by an additional 1.81% over the strongest drug-informed baseline, with PromptSE+ achieving an AUPR of 0.6878 and surpassing traditional “state-of-the-art baseline” approaches for adverse effects prediction. A paired bootstrap test showed a mean AUPR difference of 0.012, with a 95% confidence interval of 0.008-0.013.
The quality of the AI-generated profiles was also tested using a Kolmogorov-Smirnov (KS) test, which measures how well a model separates related from unrelated side-effect pairs. The LLM-derived representations achieved a KS score of 0.3939, vastly outperforming basic textual descriptions (KS = 0.0195). This supported the finding that PromptSE more effectively grouped side effects by pharmacologically relevant relationships rather than by superficial linguistic similarities.
Conclusions
The present study addresses important limitations in the data and predictive power of conventional computational drug-adverse event predictive models. It successfully demonstrates that guided reasoning, which prompts the model to consider chemical and biological drivers of side effects, can be leveraged to enable current-generation AI models to generate more informative representations and improved predictions of the potential side effects of a specific drug.
Furthermore, although this framework was specifically tested for side effects, the paradigm could potentially be applied to predict drug-drug interactions or to discover new therapeutic uses for existing medications. However, further validation using external datasets, curated pharmacological knowledge bases, and published pharmacological evidence will be needed to strengthen its biological grounding and generalizability. In conclusion, the present study indicates that integrating structured AI reasoning with deep learning has the potential to significantly accelerate drug discovery and improve computational approaches to patient safety.
[ad_2]
Source link