
Table of Contents
This blog is jointly written by Amy Chang, Idan Habler, and Vineeth Sai Narajala.
Prompt injections and jailbreaks remain a major concern for AI security, and for good reason: models remain susceptible to users tricking models into doing or saying things like bypassing guardrails or leaking system prompts. But AI deployments don’t just process prompts at inference time (meaning when you are actively querying the model): they may also retrieve, rank, and synthesize external data in real time. Each of those steps is a potential adversarial entry point.
Retrieval-Augmented Generation (RAG) is now standard infrastructure for enterprise AI, allowing large language models (LLMs) to obtain external knowledge via vector similarity search. RAGs can connect LLMs to corporate knowledge repositories and customer support systems. But that grounding layer, known as the vector embedding space, introduces its own attack surface known as adversarial hubness, and most teams aren’t looking for it yet.
But Cisco has you covered. We’d like to introduce our latest open source tool: Adversarial Hubness Detector.
The Security Gap: “Zero-Click” Poisoning
In high-dimensional vector spaces, certain points naturally become “hubs,” which means that popular nearest neighbors can show up in results for a disproportionate number of queries. While this happens naturally, these hubs can be manipulated to force irrelevant or harmful content in search results: a goldmine for attackers. Figure 1 below demonstrates how adversarial hubness can impact RAG systems.
By engineering a document embedding, an adversary can create a “gravity well” that forces their content into the top results for thousands of semantically unrelated queries. Recent research demonstrated that a single crafted hub could dominate the top result for over 84% of test queries.
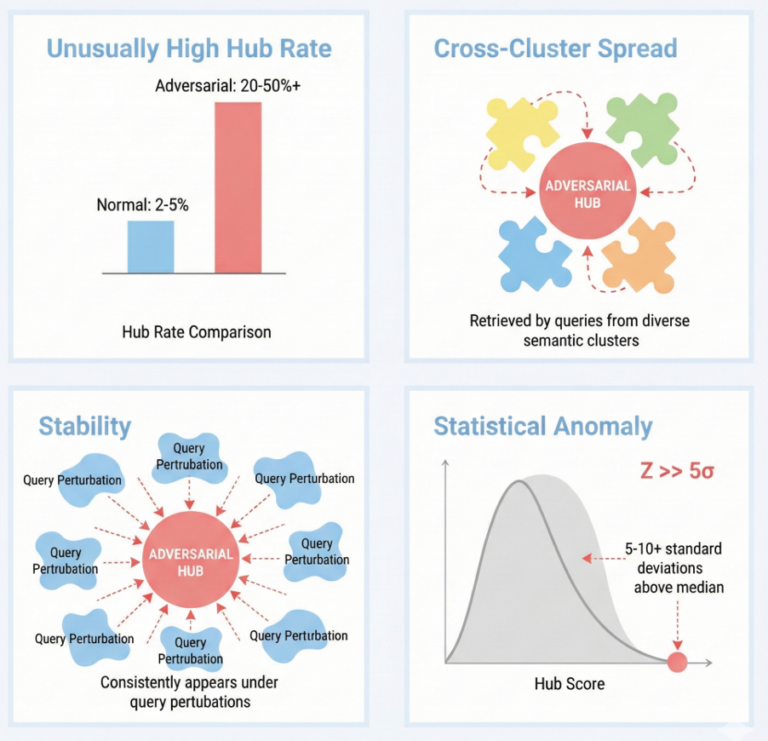
Figure 1. Key detection metrics and their interpretation: Hub z-score measures statistical anomaly, cluster entropy captures cross-cluster spread, stability indicates robustness to perturbations, and combined scores provide holistic risk assessment.
The risks aren’t theoretical, either. We’ve already observed real-world incidents, including:
- GeminiJack Attack: A single shared Google Doc with hidden instructions caused Google’s Gemini to exfiltrate private emails and documents.
- Microsoft 365 Copilot Poisoning: Researchers demonstrated that “all you need is one document” to reliably mislead a production Copilot system into providing false facts.
- The Promptware Kill Chain: Researchers created hubs that acted as a primary delivery vector for AI-native malware, moving from initial access to data exfiltration and persistence.
The Solution: Scanning the Vector Gates with Adversarial Hubness Detector
Traditional defenses like similarity normalization can be insufficient against an adaptive adversary who can target specific domains (e.g., financial advice) to stay under the radar. To remedy this gap, we are introducing Adversarial Hubness Detector, an open source security scanner designed to audit vector indices and identify these adversarial attractors before they are served to your users. Adversarial Hubness Detector uses a multi-detector architecture to flag items that are statistically “too popular” to be true.
Adversarial Hubness Detector implements four complementary detectors that target different aspects of adversarial hub behavior:
- Hubness Detection: Standard mean-and-variance scoring breaks down when an index is heavily poisoned because extreme outliers skew the baseline. Our tool uses median/median absolute deviation (MAD)-based z-scores instead, which demonstrated consistent results across varying degrees of contamination during our evaluations. Documents with anomalous z-scores are flagged as potential threats.
- Cluster Spread Analysis: Legitimate content tends to cluster within a narrow semantic neighborhood. But adversarial hubs are engineered to surface across diverse, unrelated query topics. Adversarial Hubness Detector quantifies this using a normalized Shannon entropy score based on how many semantic clusters a document appears in. A high normalized entropy score would indicate that a document is pulling results from everywhere, suggesting adversarial design.
- Stability Testing: Normal documents drift in and out of top results as queries shift. But adversarial hubs maintain proximity to query vectors regardless of perturbation, another indicator of a poisoned embedding.
- Domain & Modality Awareness: An attacker can evade detection by dominating a specific niche. Our detector’s domain-aware mode computes hubness scores independently per category, catching threats that blend into global distributions. For multimodal systems (e.g., text-to-image retrieval), its modality-aware detector flags documents that exploit the boundaries between embedding spaces.
Integration and Mitigation
Adversarial Hubness Detector is designed to plug directly into production pipelines and this research forms the technical foundation for Supply Chain Risk offerings in AI Defense. It supports major vector databases—FAISS, Pinecone, Qdrant, and Weaviate—and handles hybrid search and custom reranking workflows. Once a hub is flagged, we recommend scanning the document for malicious content.
As RAG utilization becomes standard for enterprise AI deployments, we can no longer assume our vector databases will always be trusted sources. Adversarial Hubness Detector provides the visibility needed to determine whether your model’s memory has been hijacked.